
1. Normalform:
Die einzelnen Tabellen stellen die Relationen dar, auf die untereinander über Beziehungen zugegriffen werden kann. (Zweidimensionale Tabellen die in Beziehungen zueinander stehen).
Referenzielle Integrität:
Gewährleistet das die Daten korrekt gespeichert werden, und keine Inkonsistenzen entstehen. z.B. ein Mietauto in der Mastertabelle gelöscht wird, obwohl dieses noch in der Verleihtabelle ausgeliehen ist.
Redundanz:
Redundanzen (Mehrfach das selbe) sind zu vermeiden, da sich dadurch
Inkonsistenzen bilde können. (z.B. Wenn die Adresse eines Lieferanten mehrfach
abgespeichert wird, ein Tippfehler und schon hat man z.B. 2 verschiedene
Liefereradressen.). Es ist nicht sinnvoll bei jedem Artikel den Lieferer
nochmals komplett einzutragen => Man erhält Redundanzen.
In diesem Falle sollte der Lieferer in deiner Lieferertabelle 1x gespeichert
werden und dessen Schlüssel wird bei den Artikeln mitaufgenommen.
Inkonsistenzen:
Fehler in der Datenbank. Ein nicht korrektes Abspeichern der Daten oder fälschliches Abspeichern der Daten bringt Inkonsistenzen.
Konsistenz:
Die richtige und korrekte Datenhaltung nennt man Konsistenz. Unser Ziel ist diese Konsistenz zu schaffen.
Transitive Abhängigkeiten:
Wenn eine Spalte (Attributwert) sich nicht auf das Primärschlüsselfeld bezieht, sondern auf ein anderes Feld in dieser Tabelle, so besteht eine transitive Abhängigkeit. Diese Informationen sind dann aus dieser Tabelle (Relation) zu entfernen, in einer neuen Tabelle zu pflegen und die Beziehung zwischen den beiden Tabellen herzustellen.
Primärschlüssel:
Der Primärschlüssel dient der eindeutigen Identifizierung eines Datensatzes. Er muss immer eindeutig sein und darf nicht doppelt vergeben werden.
Attribute:
Die Attribute sind die übrigen Spaltenüberschriften die sich auf das Primärschlüsselfeld beziehen.
Datensatz (Tupel):
Ein Datensatz (auch Tupel genannt) ist genau eine Zeile in der Tabelle (Entity).
Beziehungen:
Unter Beziehungen versteht man, wie die einzelnen Tabellen miteinander verbunden sind. (z.B. 1:1, 1:n, n:1 oder n:m). z.B. 1 Firma hat n Drucker.
Legende für die folgenden Beispiele:
| Rote Felder | Schlüsselfelder (Primärschlüssel) |
| Schwarze Felder | Nicht Schlüsselfelder (Attributwerte) |
| Blaue Felder | Nicht Schlüsselfelder die die Beziehung zur anderen Tabelle herstellen. |
Normalisierung:
Nicht Normalisiert:
Mehrfache gleiche Einträge.(Wiederholfelder) [Normale Tabelle z.B. in
Excel].
Hier wird der Kunde von 3 Mitarbeitern aus unserer Firma betreut. (Wolfgang,
Udo, Stephan).
1. Normalform:
Die Wiederholfelder (Iterantionen) müssen aufgelöst werden.

Also: 1. Normalform = Keine Wiederholfelder
Problem: Wenn wir nun den Kunden in Mehreren Zeilen pflegen und sich dessen Anschrift ändert hätten wir viel Arbeit. (Und wir würden uns Redundanzen erstellen.)
Beispiel:

2. Normalform:
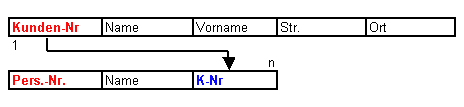
1 Kunde hat n Mitarbeiter die Ihn betreuen.
Beispiel:
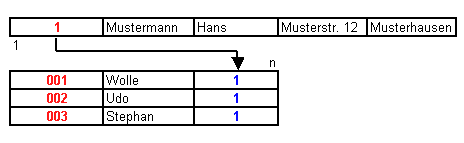
Problem:
Was tun, wenn nun der Mitarbeiter Udo noch andere Kunden betreuen soll? In diesem Falle wird dann eine Hilfstabelle erstellt, mehr dazu werde ich im weiteren Verlauf dieses Dokumentes erläutern
3. Normalform:
In der 3. Normalform werden die transitiven Abhängigkeiten aufgelöst.
z.B. Alle Felder beziehen sich auf den Primärschlüssel, außer das Feld
Skonto, dieses bezieht sich auf die Spalte Kunden-Art. Somit liegt eine
transitive Abhängigkeit vor.
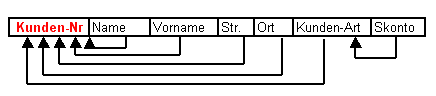
Die Attribute (Name, Vorname, Str, Ort und Kunden-Art) beziehen sich auf den
Primärschlüssel Kunden-Nr.
Das Attribut (Skonto) bezieht sich auf die Kunden-Art (Nichtschlüsselfeld)
[Guter Kunde = 3%, Schlechter Kunde = 0%]. Somit liegt eine Transitive
Abhängigkeit vor.
Lösung:


Nun sind die transitiven Abhängigkeiten aufgelöst, da jetzt in jeder
Tabelle jedes Nicht Schlüsselattribut nur noch vom Primärschlüssel abhängig
ist. (Jede Spalte bezieht sich auf das Schlüsselfeld).
In diesem Beispiel wird unterschieden zwischen "Guten Kunden" und
"Schlechten Kunden".
Beispiel einer einfachen Datenbank:
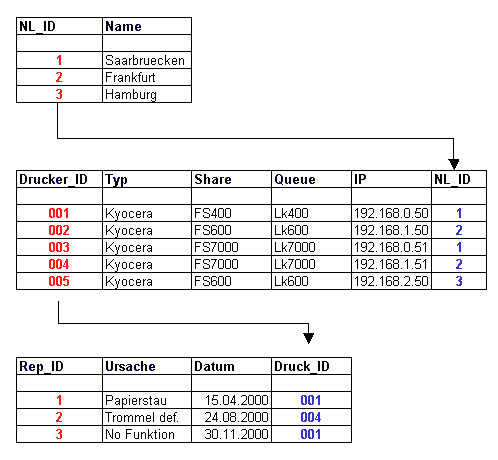
Wir stellen uns vor, wir wären die Zentrale für weitere extern ausgelagerte Niederlassungen unseres Unternehmens und würden diese verwalten. Nun wollen wir z.B. die Drucker aller Niederlassungen in einer Datenbank verwalten um schnell und effizient Informationen zu erhalten.
Um uns den Aufbau einer Datenbank etwas besser vorstellen zu können, gibt es ein recht gutes Konzept, das ER-Modell (Entity Relationship Modell).
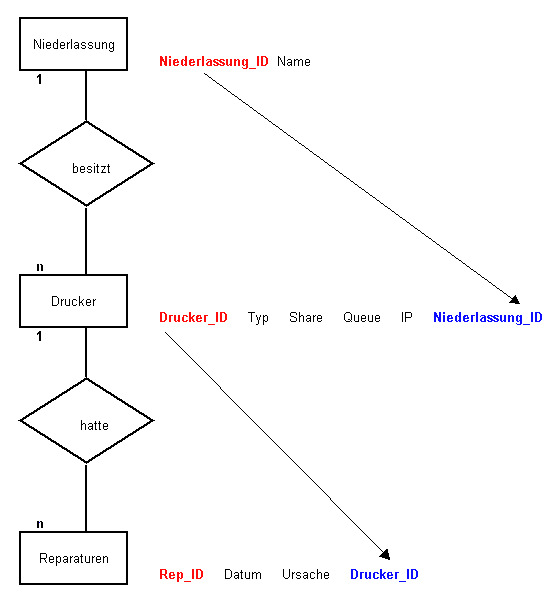
Eine Niederlassung hat "n" Drucker und 1 Drucker hatte z.B. schon mehrere Reparaturen oder es lässt sich feststellen ob noch Garantie für diesen Drucker existiert.
Die Tabellen zum vorgegangenen Beispiel:
Komplexere Strukturen:
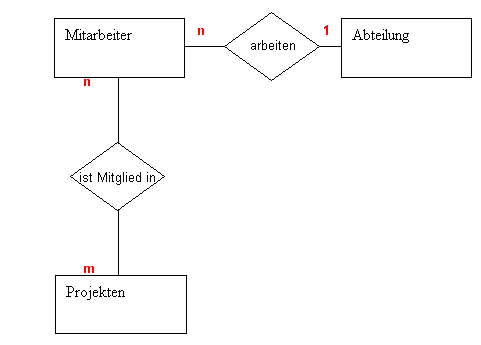
Mehere Mitarbeiter arbeiten an mehreren Projekten. Wir haben aber immer nur eine Zeile pro Datensatz. (Für Projekte wie für Mitarbeiter). Man kann den Mitarbeiter nicht 2 Mal erfassen, nur weil er an 2 Projekten arbeitet.
In diesem Falle "hilft" man sich mit einer Hilfstabelle. (wie schon zuvor erwähnt).
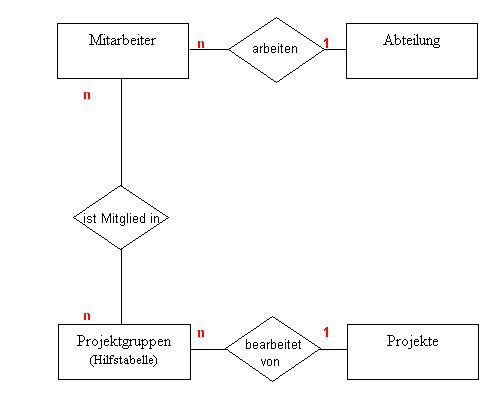
Die Tabellen zum vorgegangenen Beispiel:

Hier wird in der Hilfstabelle klar, dass nun für jeden Mitarbeiter in einer Zeile ein Projekt steht. Die laufende Nummerierung gewährleistet, die einzelnen Datensätze eindeutig zu identifizieren. Zwar kann ich mir so anzeigen lassen wer an welchem Projekt sitzt. (z.B. mit der Abfrage: „Liste alle Mitarbeiter die in Projekt 2 arbeiten auf“ in diesem Falle (Udo, Wolle und Joachim) wenn aber ein Mitarbeiter das Projekt verlässt, kann dieser nicht einzeln gelöscht werden. Durch die Laufende Nummerierung kann allerdings wolle gelöscht werden und die beiden anderen bleiben bestehen.
| 2 | 4110 (Hans) | P2 | |
| 3 | 4112 (Daniel) | P2 | löschen von Datensatz 3 |
| 4 | 4113 (Rudi) | P2 |